
I’ve build a musculoskeletal reinforcement learning environment for studying motor control using modern methods from computer science, neuroscience, biomechanics, etc.
I’ve set up a competition to build models of the brain in the crowdAI. Competition was accepted as one of the 5 official competitions at NIPS 2017 and one of 8 competitions at NIPS 2018, attracting over 500 teams from all over the world.
Here are some solutions from the first challenge
You can find the code on the official website.
Getting started
Anaconda is required to run our simulations. Anaconda will create a virtual environment with all the necessary libraries, to avoid conflicts with libraries in your operating system. You can get anaconda from here https://www.continuum.io/downloads. In the following instructions we assume that Anaconda is successfully installed.
For the challenge we prepared OpenSim binaries as a conda environment to make the installation straightforward
We support Windows, Linux, and Mac OSX (all in 64-bit). To install our simulator, you first need to create a conda environment with the OpenSim package.
On Windows, open a command prompt and type:
conda create -n opensim-rl -c kidzik opensim python=3.6.1
activate opensim-rl
On Linux/OSX, run:
conda create -n opensim-rl -c kidzik opensim python=3.6.1
source activate opensim-rl
These commands will create a virtual environment on your computer with the necessary simulation libraries installed. Next, you need to install our python reinforcement learning environment. Type (on all platforms):
conda install -c conda-forge lapack git
pip install git+https://github.com/stanfordnmbl/osim-rl.git
If the command python -c "import opensim" runs smoothly, you are done! Otherwise, please refer to our FAQ section.
Note that source activate opensim-rl activates the anaconda virtual environment. You need to type it every time you open a new terminal.
Basic usage
To execute 200 iterations of the simulation enter the python interpreter and run the following:
from osim.env import ProstheticsEnv
env = ProstheticsEnv(visualize=True)
observation = env.reset()
for i in range(200):
observation, reward, done, info = env.step(env.action_space.sample())
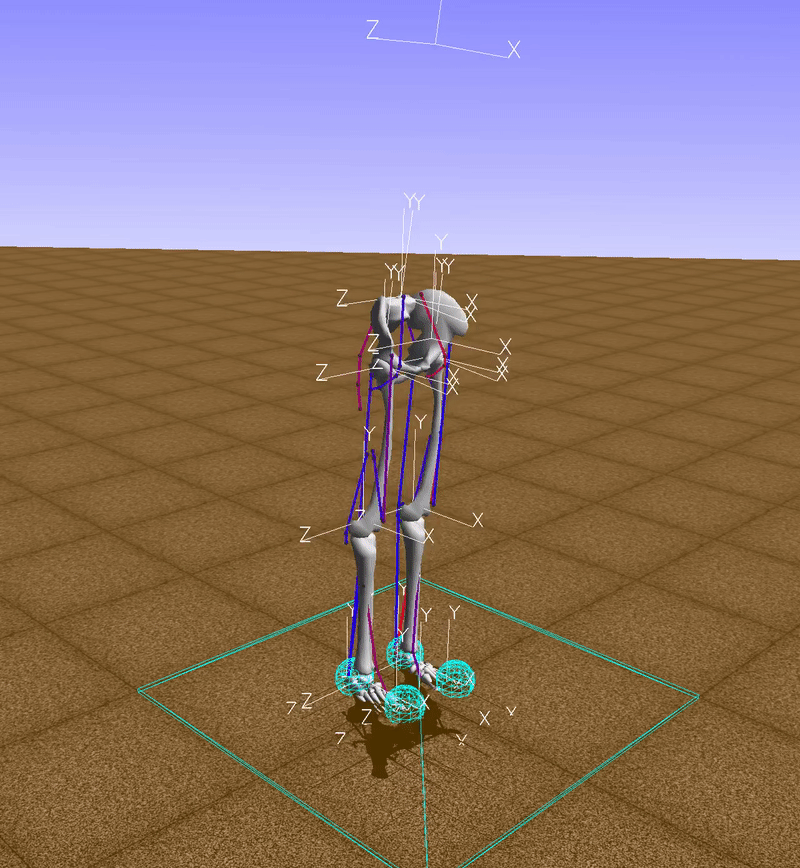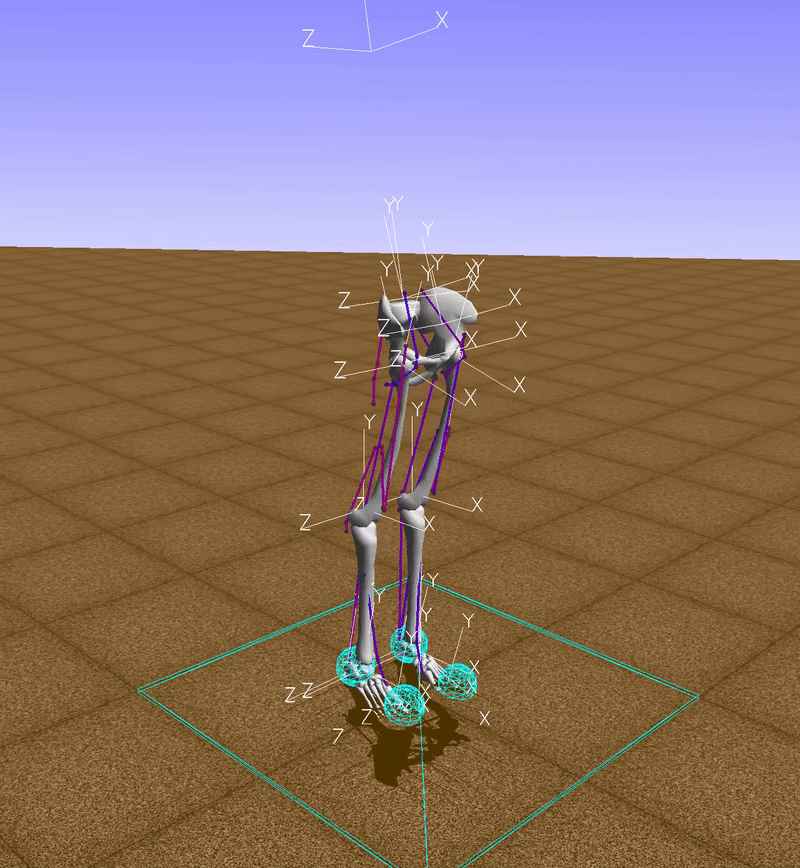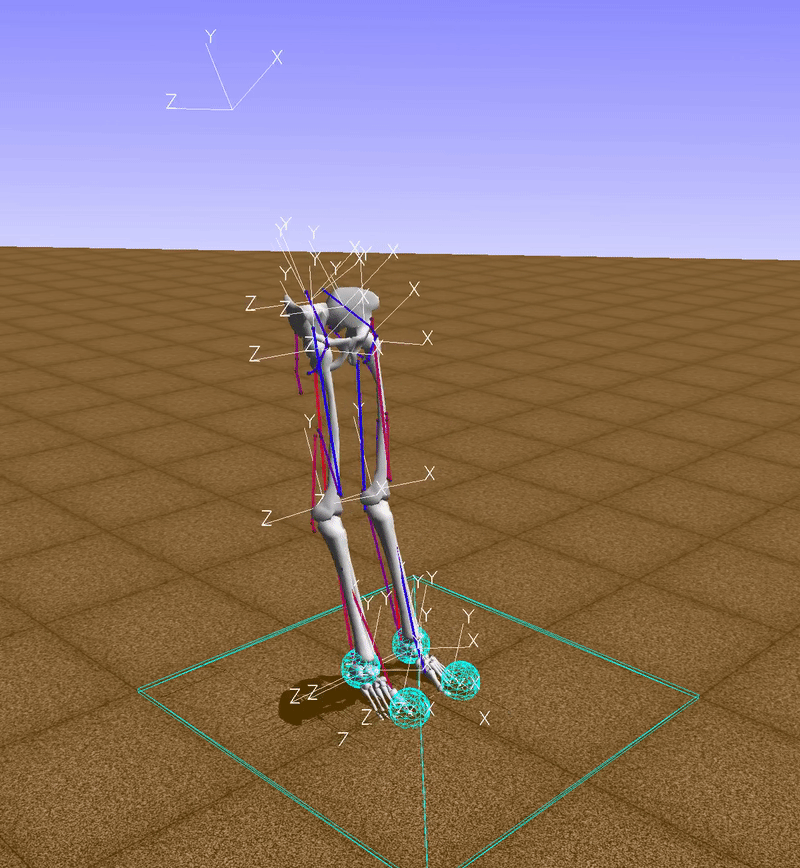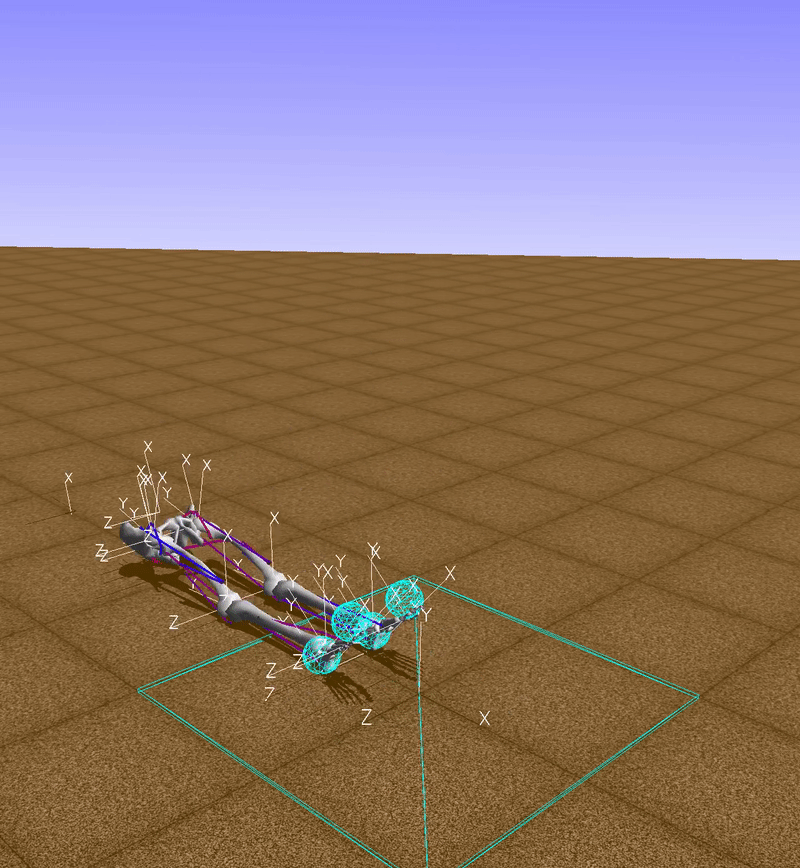
The function env.action_space.sample() returns a random vector for muscle activations, so, in this example, muscles are activated randomly (red indicates an active muscle and blue an inactive muscle). Clearly with this technique we won’t go too far.
Your goal is to construct a controller, i.e. a function from the state space (current positions, velocities and accelerations of joints) to action space (muscle excitations), that will enable to model to travel as far as possible in a fixed amount of time. Suppose you trained a neural network mapping observations (the current state of the model) to actions (muscle excitations), i.e. you have a function action = my_controller(observation), then
# ...
total_reward = 0.0
for i in range(200):
# make a step given by the controller and record the state and the reward
observation, reward, done, info = env.step(my_controller(observation))
total_reward += reward
if done:
break
# Your reward is
print("Total reward %f" % total_reward)
You can find details about the observation object here.